Creating Discourse permalinks with shell commands
The other day, I deleted a bunch of categories in Discourse. In the process, I broke a bunch of links. I hate breaking links, but it just never occurred to me that deleting categories would break links too. But, of course, Discourse can’t know that I moved all these topics to school-specific tags that should replace the school-specific categories.
The pattern for redirection is extremely simple:
c/musical-theater-schools/american-university-mt/658
=> tag/american-university-mtc/musical-theater-schools/american-university-mt/658It’s not all that hard to do this by hand, but I have 58 permalinks I need to create! This sort of work is pretty mindless. I could probably do it while watching a single sitcom episode. But it’s also extremely easy to mess up if you aren’t paying enough attention. Writing a quick script can be nearly as easy and a lot more enjoyable. So that’s what I’m going to do in this case. (And make it take even longer by writing this post at the same time.)
Discourse supports permalinks and it’s not hard to reverse engineer the API for inserting them. The first thing I did was to insert a sample permalink using the admin interface:
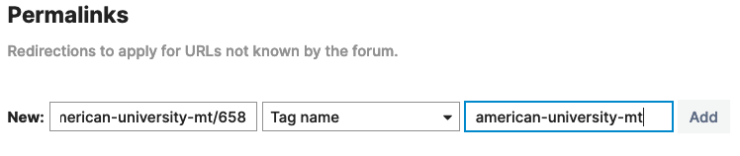
From the developer interface, I see the request is to
/admin/permalinks.json with the following payload:
url=c%2Fmusical-theater-schools%2Famerican-university-mt%2F658&permalink_type=tag_name&permalink_type_value=american-university-mtConverting that into a more readable format:
url = "c/musical-theater-schools/american-university-mt/658"
permalink_type = "tag_name"
permalink_type_value = "american-university-mt"So those are the three parameters I need. url is the URL
I want to redirect, so it’s my input. permalink_type is
static. I always want the link to point to a tag.
permalink_type_value is the place I want to redirect to. In
this case, it’s the tag name I want to point to instead of the category.
Thankfully, I created
the tags using the category slug, so I just need to extract that
substring from the url.
The steps I need to do are:
- Get a list of category URLs that I removed.
- Extract the tag name from each URL.
- Post a request to
/admin/permalinks.jsonwith the correct parameters.
When writing a shell script, it’s often easiest to start with the last step and work forward. So if I can post one request with hardcoded values, I know I can build a request based on one URL. And if I have a command that parameterized one URL, I can iterate over a list of URLs.
To put it another way, shell scripts often take the form of a pipeline:
$ first_command | middle_command | last_commandSince the last command produces the output you want, it’s important to give it the input it needs. So there’s no point in starting the middle command (much less the first command) before you know what the last command is going to need.
The final step, in this case, is a call to the Discourse API. Whenever you hear “API” in the context of shell scripting, you should think “curl”. I’m going to skip over a few steps I took reminding myself how curl works and jump straight to the sample command I executed:
curl $DISCOURSE_HOST/admin/permalinks.json \
-H "Api-Username: $DISCOURSE_USER" \
-H "Api-Key: $DISCOURSE_API" \
-d "url=/c/musical-theater-schools/american-university-mt/658&permalink_type=tag_name&permalink_type_value=american-university-mt"I’ve put a few bits of data behind environment variables to make life
easier when I move from testing commands to executing them on production
servers. $DISCOURSE_HOST is the host I’m working on. In my
case it’s set to https://talk.collegeconfidential.com when I’m ready to
try commands on production. $DISCOURSE_USER is my username
on the site. (I’m CCadmin_Jon
on College Confidential.) $DISCOURSE_API is an API key I
generated by visiting /admin/api/keys on a Discourse site
where I’m an admin. Only admins can create API keys (or parmalinks).
The part I need to change is the -d parameter. It should
look somewhat familiar since same payload I got from the dev tools when
using the site interface. It has two parts that are variable:
- /c/musical-theater-schools/american-university-mt/658
- american-university-mt
Extracting the category slug can be done several different ways. sed is probably the right choice, but I’m going to use something less obvious:
$ dirname /c/musical-theater-schools/american-university-mt/658 | xargs basename
american-university-mtdirname selects everything before the last
/ and basename selects everything
after the last slash. xargs is my go-to tool
for chaining commands. If basename accepted arguments form
standard input, it wouldn’t be necessary. (Spoiler alert: I’m going to
use xargs again later on.)
At this point, I’m going to start putting my script into a file so
that it’s easier to edit. I’m going to call it
create_permalink.ksh and it looks like this:
#!/usr/bin/env ksh
u=$1
t=`dirname $u| xargs basename`
curl $DISCOURSE_HOST/admin/permalinks.json \
-H "Api-Key: $DISCOURSE_API" \
-H "Api-Username: $DISCOURSE_USER" \
-d "url=$u&permalink_type=tag_name&permalink_type_value=$t"Before I can use it the first time, I need to make it executable:
chmod +x create_permalink.kshThen I can test it:
$ ./create_permalink.ksh /c/musical-theater-schools/american-university-mt/658
{"status":500,"error":"Internal Server Error"}% I’m getting an internal server error because I’ve already created this permalink. Actually I’ve created it several times for testing and removed it using the admin interface on the site.
Now there are some shell oddities in the script that you might not be familiar with. So I’ll go over it one command at a time:
#!/usr/bin/env kshThis tells the interactive shell which interpreter to use. I’m a fan of ksh, but it
should work with any Bourne shell
descendant. I could have used #!/usr/bin/ksh or even
just #!ksh, but the more complicated command is slightly more
potable.
u=$1I’m putting the URL in a variable called $u. This
commend sets the variable using the value of the first input parameter.
It’s a bit unnecessary since I could just use $1 everywhere
in the script. But I got the habit of assigning arguments to variables
so that I could use
"$@" for lists of parameters. It also is slightly more
readable if you name your variables instead of number them.
t=`dirname $u| xargs basename`The tag name goes in $t. I’m using backticks (`) to capture the output
of the command I mentioned above for extracting the category slug.
The more modern method would be to use $(...) instead.
curl $DISCOURSE_HOST/admin/permalinks.json \
-H "Api-Key: $DISCOURSE_API" \
-H "Api-Username: $DISCOURSE_USER" \
-d "url=$u&permalink_type=tag_name&permalink_type_value=$t"This is a single curl command put on separate lines. The only thing I changed is making the URL and the tag string variables.
Now I can do a bunch of permalinks by running this command several times. I could set up a for loop in my script:
for u in "$@"
do
t=`dirname $u| xargs basename`
curl $DISCOURSE_HOST/admin/permalinks.json \
-H "Api-Key: $DISCOURSE_API" \
-H "Api-Username: $DISCOURSE_USER" \
-d "url=$u&permalink_type=tag_name&permalink_type_value=$t"
doneOr I can pipe the list into xargs:
$ echo $urls | xargs -n 1 ./create_permalink.kshBut how do I get a list of the categories I’ve already deleted? I figured out that there was a problem because we noticed 404s in Google’s Search Console, so I could pull the list from there. But I can also get a list from the Discourse logs, which is handy given that future mistakes might not be so easily tracked by a third party.
If you are an admin on a Discourse site, you can visit
/admin/logs/staff_action_logs to get a complete list of
actions staff have performed, including deleting categories. There’s
also a button to export the logs as a CSV
file. After downloading the file, I used less to browse
it. The first two lines helped me understand the format:
staff_user,action,subject,created_at,details,context
CCadmin_Jon,entity_export,staff_action,2021-03-09 18:40:41 UTC,,Typically the first line explains the columns, as you can see in this case. And the second line shows the very last thing that was logged, which was me requesting the log to be exported. So I know this log is reverse chronological with the most recent events listed first. That’s a bit atypical because normally log entries are appended to the CSV file as they happen. Discourse logs are stored in database tables, so they can be exported in whatever order makes the most sense.
Using / to search through the logs, I found one of my
delete_category entries.
CCadmin_Jon,delete_category,,2021-02-21 00:37:52 UTC,"created_at: 2020-11-26 11:45:12 UTCUnfortunately, that line doesn’t say which category was deleted. For that, I needed to read down a few more lines:
CCadmin_Jon,delete_category,,2021-02-21 00:37:52 UTC,"created_at: 2020-11-26 11:45:12 UTC
name: American University MT
permissions: {}
parent_category: Musical Theater Schools",/c/musical-theater-schools/american-university-mt/658It took me a bit to figure out how this entry spanned multiple lines.
The details entry includes a double quote, which signals
the start of a string. Since there is no close quote before the end of
the line, the next line is also part of the string. So the
details column ends on line 4 with the closing quote. I’m
most interested in the final column, context, which
includes the path of the category I deleted. That’s going to be my input
to create_permalink.ksh.
Allowing newlines embedded in columns is pretty handy because it
allows the log to show, for instance, the full body of a post that was
deleted. For deleting a category, it shows some metadata about the
category. But this throws a wrench in my plans to use grep
to find the row where I deleted each category and extract the path. I
didn’t sign up to parse complicated CSV files.
I could switch the Database Explorer API. But why should I when I already got the data I need in the log export? I just need to be a little creative in how I get it. Look again at the line that contains the path I’m looking for:
parent_category: Musical Theater Schools",/c/musical-theater-schools/american-university-mt/658Looking at other deleted categories, I noticed they all look the same
right up to the slug. Just as importantly, only the lines for
deleted Musical Theater School categories start with this string.
That means I can find what I’m looking for by using this
grep command:
grep 'parent_category: Musical Theater Schools",/c/musical-theater-schools/' staff-action-210309-184041.csvThis isn’t technically right. There is a universe in which this command will cause hard-to-debug problems. Which brings me to the first rule of script programming: All is fair in love and shell. Alternatively: There’s no wrong way to get the right answer. An awful lot of learning to be a programmer centers on the concept of correctness. That’s because you never know how your code will be used in the future. You have to make sure it’s robust against bad input that could make everything go very wrong.
But if you are writing a script for yourself and for a specific purpose, you don’t have to worry about it being used by someone else for some purpose where it might, I don’t know, delete their hard drive or something. But that puts the onus on you to make sure you feed your script good input. So the next thing I did was sort the list and eliminate any duplicates to make sure I had the right lines:
$ grep [big long string] [file] | sort -uFinally, I need to pull out the path. This time I will use
sed:
$ grep [big long string] [file] | sort -u | sed -e 's/^.*,//'
/c/musical-theater-schools/american-university-mt/658
/c/musical-theater-schools/baldwin-wallace-college-mt/662
/c/musical-theater-schools/ball-state-university-mt/661
...The key bit is s/$.*,//. To work out what that means,
you need to know regular expressions, which is a lot to learn. They are
incredibly useful, however, so it’s worth the effort. This command
substitutes (s/) the part of the string that matches a
pattern ($.*,) with an empty string (//). The
pattern ($.*,) begins with the start of the line
($), continues with any number of characters
(.*) until it come across a comma (,). We are
left with everything following the first comma, which is exactly what we
want to find.
After double- and triple-checking the output, I put the whole thing together and created my permalinks:
grep 'parent_category: Musical Theater Schools",/c/musical-theater-schools/' staff-action-210309-184041.csv \
| sort -u \
| sed -e 's/^.*,//' \
| xargs -n 1 ./create_permalink.ksh There’s xargs again! -n 1 is only necessary
if I don’t include the for u in "$@" loop in
create_permalink.ksh. It tells xargs to
repeatedly call the command with just one parameter each time it’s
called.
At long last, I have 58 new permalinks. I can check there were no
errors by looking at the output of each curl command:
{"permalink":{"id":406987,"url":"c/musical-theater-schools/american-university-mt/658","topic_id":null,"topic_title":null,"topic_url":null,"post_id":null,"post_url":null,"post_number":null,"post_topic_title":null,"category_id":null,"category_name":null,"category_url":null,"external_url":null,"tag_id":572,"tag_name":"american-university-mt","tag_url":"https://talk.collegeconfidential.com/tag/american-university-mt"}}% I can also go to /admin/customize/permalinks on my
Discourse host. Finally, I can check the
formerly broken link and make sure it ends up in the
right place.
If you followed me this far, I hope you enjoyed reading this and aren’t some sort of compulsive reader who somehow couldn’t change to another page to read something more enjoyable. I enjoy writing shell scripts to get work done and I certainly spent more time than needed on this one.