Why AI is a problem on Stack Overflow
There’s a scene in Fellini’s 8½ where the director character is reading a negative review of the movie he is working on (which is also, somehow, the movie we are watching). The critic speaks the review in voice-over and the voice-over abruptly stops when the director suddenly tosses the paper away.

I mention it because that scene felt like a pretty good illustration of Stack Overflow’s public response to criticism lately. The company has started a bunch of new projects, none of them are completed and the community has already deemed them failures. If my reading is correct, the CEO has launched those projects with an aggressive deadline (the CEO’s speech on July 27) and insufficient resources. Sure things look messy now. Maybe hold off judging until progress has been made, whydontcha?
It’s hard to keep up with the new projects. There’s:
- a title suggestion system,
- a tool for extracting questions from Slack,
- analysis of what developers think of AI/ML,
- a question reformatting assistant and
- a “Prompt Design” site launch.
I could be missing one or two. Tallying up these initiatives I wonder if the quantity serves to put on a show of solving the problem while keeping everyone too busy to ask inconvenient questions. It may also create esprit de corps within the company.
There’s plenty of criticism of these projects from meta users. Some of it is just angry, knee-jerk flames from people who feel slighted by the company in various ways. Still, there’s a lot of valid criticism mixed in and some of these projects are more promising than others. Seems to me Stack Overflow ought to follow the example of the 8½ director and pick up the crumpled review. It might be useful later when trying to sort out what went wrong.
I’m still stuck on something that was posted about a decade ago. [Editor’s note: just 3 weeks in reality. We’re not in a Fellini film here!] It’s the data-driven argument which undergirds company’s position that moderators have been harming Stack Overflow by incorrectly diagnosing ChatGPT answers. While I like to imagine myself as unbiased, I did sign the strike letter. So I decided to reproduce the results as best I can and “think it possible that [I] may be mistaken”.
To keep things straight, I’m borrowing the headings from the post and leaving my responses under them. Unattributed quotes will be from that post as well.
Automated GPT detectors have unusable error rates on the platform
We’re off to a good start because I actually agree with this point. I’ve had a bit of experience using these tools and they seem best used as supplementary data. Detectors often have guidance such as:
Our intended use for the AI Text Classifier is to foster conversation about the distinction between human-written and AI-generated content. The results may help, but should not be the sole piece of evidence, when deciding whether a document was generated with AI. The model is trained on human-written text from a variety of sources, which may not be representative of all kinds of human-written text.
A minor quibble though: it’s not at all clear what detector was tested since there are several distinct results when searching for HuggingFace’s GPT detector. Many of those detectors predate ChatGPT launch on November 30, 2022.1 But since nobody is arguing for just using an automated detector, I think we can leave this point alone.
The volume of users who post 3 or more answers per week has dropped rapidly since GPT’s release
It’s easy to verify this claim via SEDE. The graph is accurate, as far as it goes. What makes this graph odd is that it starts in October, 2022, shortly before ChatGPT was released. It indexes the 3+ answerers per week from that month to 1.0 and shows a sharp drop-off to nearly 0.5 this May. But we can pull back the lens to show all of Stack Overflow’s history:
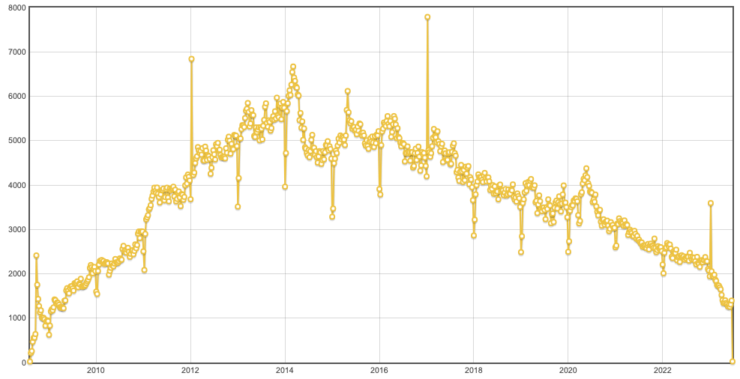
Now compare that to a graph I showed right after the strike started:
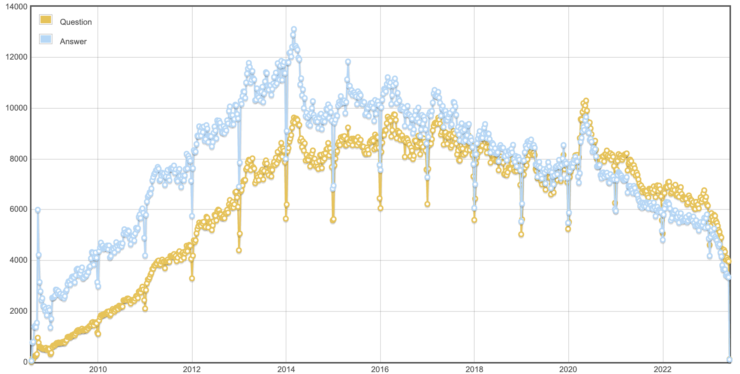
In context, the rapid drop in answerers is strongly correlated with the drop in answers and questions that’s been happening for nearly a decade. You’ll see similar patterns if you run the same queries for other active sites such as Math, Physics and Super User.2 Each site has different peaks, but the number of 3+ answerers a week has fallen off.
ChatGPT might have accelerated the problem, but I was worried about answer rates (and new answerers) back in January of 2019. Gratifying that leadership has finally taken notice of the problem though it’s disappointing the moderators are getting blamed here. In retrospect, there should have been a lot more hand-wringing when answer rates fell suddenly in 2014. Maybe we could have discovered better solutions to the problem than rolling out the Welcome Wagon yet again.
So my analysis agrees that frequent answerers are less common than in the past, but I mark the start of the trend (for Stack Overflow) in 2014 rather than October, 2022. Moderators suspending people for ChatGPT answers simply can’t be the sole cause of the problem. By cropping just to the last 9 months and by ignoring similar trends on other network sites, the company’s analysis excludes other potential factors.
The total volume of questions available to frequent answerers continues to rise
My query more or less replicates this point. Interestingly the graph shows a steady rise in questions asked per number of 3+ a week answerers until 2020. That’s the pandemic peak as people apparently got really into asking questions on Stack Overflow during lockdown. From my reading of that graph, coronavirus had a larger impact than ChatGPT.
7% of the people who post 3 or more answers in a week are suspended within three weeks
I don’t have access to this data, but from what I’ve heard from moderators and curators, people who use ChatGPT tend to answer several questions very quickly. Indeed, one of the company’s responses was to ratchet down the answer rate limit to 1 answer every 30 minutes for users with less than 125 reputation. Since the other part of the official response was to empower moderators to suspend users who copy and paste GPT without prior warning,3 it’s not surprising the people with 3 or more answers in a week would be most impacted.
Regardless of the above, no Community Manager will tell you that removing 7% of the users who try to actively participate in a community per week is remotely tenable for a healthy community. Supposing every suspension is accurate, the magnitude raises serious concerns about long-term sustainability for the site.
Well, I’m a Community Manager over at College Confidential and I would say 7% is on the high side. Most weeks we are in the 1–3% range. A few weeks ago we spiked at 9.5% and that did seem like a lot of spam. Can’t say I’m worried about the health of our community on that front. I’d be much more worried if those users hadn’t been suspended.
If I were still a CM at SO, I suspect I’d be more interested in removing the barrier from the ~10% of askers who are blocked for unformatted code. I’d recommend the developers of the question formatting assistant focus exclusively on that problem until the failure rate is under 1% or so.
If you haven’t already metaphorically tossed this critique away, I’ll anticipate the objection that ChatGPT answers aren’t spam. I agree. As we will see shortly, they are so much worse.
Users who post 3 or more answers in a given week produce about half the answers
I’m slightly irritated having to write more SQL Server SQL after spending three years using PostgeSQL. While I’m kinda curious about what I’d see if I extended the graph out a few year, this is a detour so I’m going to just stipulate this point and move on.
Yet, at the same time, actual GPT posts on the site have fallen continuously since release
We’ve arrived at the heart of the argument. It’s a description of the “gold standard” estimate of the “true” rate of GPT posts.4 I’ll quote the key paragraph:
This metric is based around the number of drafts a user has saved before posting their answer. Stack Exchange systems automatically save a draft copy of a user’s post to a cache location several seconds after they stop typing, with no further user input necessary. In principle, if people are copying and pasting answers out of services like GPT, then they won’t save as many drafts as people who write answers within Stack Exchange. In practice, many users save few drafts routinely (for example, because some users copy and paste the answer in from a separate doc, or because they don’t stop writing until they’re ready to post), so it’s the ratio of large draft saves to small draft saves that actually lets us measure volume in practice.
This is a brilliant concept and I’m half persuaded just from how clever the idea is. Before the draft feature was implemented, I learned to write answers in my editor of choice (Emacs) so that my draft wasn’t lost if my browser crashed or I had to reboot my computer. I could take hours or even days to finish an answer and I got burned too many times. It took me awhile to break the habit after the draft feature was implemented and there are certainly others who edit off site to this day. So any increase above that baseline that started in December 2022 could very well be the result of people pasting in ChatGPT answers.
The chart has a few issues, however:
- It starts in October, 2022, so we only have a small amount of context. Is the October baseline representative of the 12 years in which drafts were saved? Strange things usually happen in December, so was this metric flat in previous Christmas seasons?
- There’s an odd gap in the raw data during late February. I can mentally fill in the gap and it does match the smoothed curve well enough. But not explaining the gap sets off an alarm.
- I’m incredibly curious about what this looks like in other sites on the network. While other sites are a lot smaller than Stack Overflow, the rest of the network adds up to what ought to be sufficient data.
- My prior would be for ChatGPT usage to increase as public interest increased through the early part of 2023. I’m not an early adopter, so I didn’t pay much attention to ChatGPT until mid-March. I didn’t consider the possibility of using it for coding projects before I read “Cheating is All You Need” a few weeks later. It seems quite unlikely that fewer people would be using ChatGPT to answer Stack Overflow questions after it broke into the public conscious than before.
That last point deserves to be brought out of the list. OpenAI has played the Rogers curve perfectly. But you can’t convince me that ChatGPT reached a peak in December. It’s not just anecdotal evidence5 either. Google Trends clearly shows interest accelerated from January through at least the beginning of April:
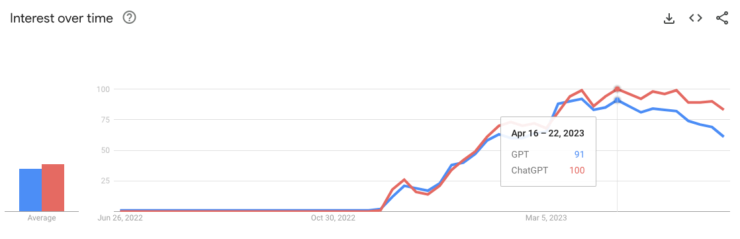
I don’t want to add too many graphs, but you can see the same trend on “GPT” comments on the network (excluding Metas and Stack Overflow).6 My point in all of this is that I’d expect people to be trying out answering with ChatGPT more often as the technology became more widely known (and even adopted). The data showing a decrease from a peak in December rather than an expected increase through March suggests two possible conclusions:
- Stack Overflow’s previous policy banning GPT-generated answers worked incredibly well or
- the “gold standard” is mistaken.
I’m setting these ideas in opposition because I believe they represent the best argument the company can make versus the best argument the moderators can make. The first is not unreasonable on it’s face because the company-approved policy was quite aggressive. It appears the company has concluded the moderators took their policy and applied it well beyond GPT-generated answers. (We’ll address that theory more in a bit, but it should be noted that moderators generally suspended users for 7 days rather than the staff-suggested 30 days.)
But I also think the draft count metric stopped working because the ChatGPT ban was effective. When you block people from doing what they intend to do, they sometimes adjust their behavior. Just as spammers developed tricks to avoid detection, I believe people posting ChatGPT answers learned to edit their posts to hide their origin.
How drafts get saved
In order to test the hypothesis that ChatGPT answers require just one save, I decided to use ChatGPT to draft some answers. I started by visiting a random question on Stack Overflow. Then I copied either the body of the question or, if it seemed descriptive enough, just the title. I pasted that into ChatGPT and pasted its output into the answer box under the question. I also popped open the developer tools and looked at the Network tab to see what was being passed back to the server:
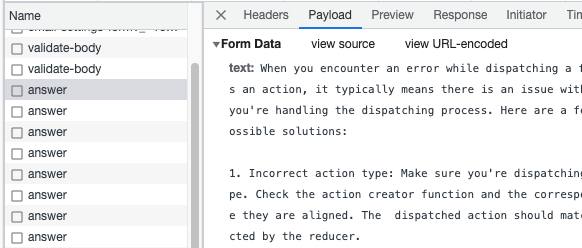
You can see in the screenshot there are two network requests that I observed as I edited my answer:
validate-bodywhich sends the text of the body in a payload and usually responds:{"success":true,"errors":{},"warnings":{},"source":{}}. Presumably it will send a different response if the body of the answer can’t be validated.answeris a heartbeat request which only sends the text if the body has changed. In that case, it returns (among other things)"draftSaved": true. If the body hasn’t changed, the payload doesn’t include the text and the return is"draftSaved": false. So this is the API call that saves drafts shortly after an edit.
When I paste in my ChatGPT answer, see two validate-body
requests followed by an answer. If I leave the answer alone
for 45 seconds, the heartbeat fires off with a nearly empty payload. If
I type into the answer box, the request patiently waits until I’m done
typing and sends another validate-body and
answer with my updated draft. While it’s the
answer API call that actually saves drafts, you can tell
there will be a draft to save every time validate-body is
fired off. There’s also a green “Draft saved” notice under the post that
vanishes when you type.
If I were to simply paste in an answer and post it, there would be exactly one draft sent to the server. I’m confident that if Stack Overflow is seeing more of these sorts of answers since November 30, 2022, the excess over the baseline accurately reflects naive usage of ChatGPT. But given Stack Overflow’s initial anti-GPT policy, there’s a good chance people using ChatGPT got a bit more sophisticated than simply pasting in answers.
A case study
Let’s take a specific example. In 2018, I struggled to debug some R code I was using to query our internal copy of the Stack Exchange database (“localsede” if memory serves). After I solved the immediate problem, I decided to ask a question on Stack Overflow to see if there were a way to get better error messages in the future. After a few comments, the question lay fallow for a few years.
Then in April 2022, I got a detailed comment from r2evans, who is a prolific R answerer, saying that the problem has been resolved in recent updates. Unfortunately, I couldn’t test the answer since I was no longer a Stack Exchange employee and didn’t have access to the internal database. Again it went quiet, but the question continued to gather votes.
On December 3, 2022, just three days after the release of ChatGPT, I got an actual answer. (It was deleted, so you’ll need to have at least 10k reputation on Stack Overflow to see these pages.) It had some useful information, but the author made the mistake of adding another line to the end of the answer:
I hope this helps! Otherwhise, try https://chat.openai.com/chat
Two things to notice:
- It’s almost certain the answer was generated by ChatGPT since that’s the clear implication of adding the link.
- Adding that line would mean that at least two drafts were sent.
My guess is that this would still be counted in the “small draft saves” bucket.7
Another sorta odd thing about this answer is it commented out the
ORDER BY line in the code and explained:
I’ve commented out the ORDER BY clause in the example above, but you can remove the comment if you want to include it in your query.
This is notably because I regenerated answers to my question 10 times
on ChatGPT and not once did the model mention that the crux of my error
was ORDER BY. In addition, as I said before, the model
generally uses backticks to format inline code and didn’t in this case.
My guess is that this user spent a few minutes understanding the problem
and tailored the answer to fit the question. That’s a good thing!8 It also means you can add at least
one more draft to the mix.
My point is that even early on some people were not naively copying and pasting answers from ChatGPT to Stack Overflow. The answer in question was deleted a few days later under the temporary policy that banned ChatGPT. The incentives created by the ban would also encourage more edits to hide the provenance of machine-generated answers.
Even though AI detectors have mixed records, humans have unparalleled pattern recognition talents. On December 4, Andrew Shearer posted about experimenting with ChatGPT answers on Stack Overflow. He noted that other people were doing the same thing:
I can confidently say though, I was NOT the only one doing this. If you have used ChatGPT to answer coding questions, you may have noticed it uses the same terminology very often in its responses. I noticed that it after it was done explaining why the code wasn’t working, or explaining steps I should take for what I wanted to accomplish, right before the code snippet, it would say something like:
“Here is an example of how you would do X:”
A commenter on Hacker News reported:
And I’m starting to recognize the “voice” of this thing now and it’s driving me crazy. The content is so bland, the conclusions so plainly obvious.—plasticchris on December 5, 2022
There are ways to prompt ChatGPT to be less obvious. For instance, you can ask it to answer in plaintext rather than Markdown. The default style resembles a competent, if dry, Stack Overflow answer. There are other styles you can request (another commenter suggested “angry Hacker News commenter” which does work, but likely won’t help you get upvotes on Stack Overflow.
Based on an
observation from Makyen, I decided to offer a bounty on my question.
Sure enough, I got another
answer which is currently live on the site. It suggests using
tryCatch(), which is what about half of the ChatGPT answers
I generated suggest. (That misses the point of my question, by the way.)
This answer doesn’t use backticks. It rather bizarrely puts R code in Stack
Snippets which are designed for JavaScript, CSS and HTML. It doesn’t
work to try to run R code there. While I can’t prove this is
ChatGPT-generated, it closely resembles the answers I generated on my
own.
If it was from ChatGPT, the user made at least one adjustment to the
text. Most of the prose is grammatically pristine, but the code is
introduced with this odd sentence: “Try to modify your code as below.”
As Andrew Shearer mentioned, ChatGPT invariably uses “Here’s an
example”. I mean 10 out of 10 answers I generated use these exact words.
So it’s smart to change things up a bit. Then to match this phrasing, ya
gotta do a quick s/example/modified code/g.
So that’s one draft for pasting in, one draft for putting code in a Stack Snippet, one draft for editing the standard code introduction and maybe one more for editing other examples of “example”. Possibly a few other edits to remove repetition? Is that enough to take this out of the “small draft saves” bucket? Who knows.
We’ve fallen deep in the weeds here, so now is a good time for a recap:
- The drop in frequent answerers represents an acceleration of long-term trends.
- Since ChatGPT launched, people who answered 3+ questions in a week are more likely to be suspended than in the past.
- Interest in ChatGPT increased rapidly from its launch through April of this year.
- Simply copying and pasting answer from ChatGPT to Stack Overflow leaves obvious artifacts that the text came from ChatGPT unless the answer is edited, thereby triggering more saved drafts.
- Therefore, the company’s “gold standard” which shows decreasing GPT posts might be missing changes in behavior caused by the company’s temporary ban of ChatGPT posts.
Many of GPT appeals sent to the Stack Exchange support inbox could not be reasonably substantiated
One of my earliest topics on this blog was how the community support inbox worked. Community managers constantly evaluate appeals of moderator decisions. When policies change (banning ChatGPT, for instance) CMs can expect people to use the support system to appeal moderator decisions. Here’s how the meta post explained what happened:
As a platform, we have an obligation to ensure that moderation actions taken on the Stack Exchange network are accurate and can be verified upon review if we need to do so. We need to be able to see, understand, and assess whether the actions taken were correct. It therefore needs to be said that we are very rarely, if ever, in the position where we cannot do so. In all other areas for which we receive suspension appeals, moderator actions are easily verified and double-checked the overwhelming majority of the time. It is rare and notable if we are ever in the position of overturning a moderator’s decision due to insufficient or contradictory evidence.
So, when we say that many of the GPT appeals we receive could not be substantiated on review, please keep in mind that our baseline value for this is zero, and it’s been that way for years. It is exceptionally strange for us to look at a moderator’s action and find ourselves unable to verify it – yet this is the situation we are frequently in with respect to GPT.
Something about this feels off and it took me several weeks of passively thinking about it to nail down the problem. It’s not in what’s said, but what’s unsaid. When I get complaints about moderators (I got one this week on the site I currently manager) I try to reconstruct what happened from the user’s perspective. Almost always the user fails to understand the site rules or the role of volunteer moderators. I carefully (and frequently quixotically) explain the situation to the user in response and close the ticket. There’s no need to contact the moderator because they did what they ought to.
Very rarely, I discover a moderator has abused their authority. In that case, I undo their actions and take the moderator aside privately to discuss it. If it’s a discussion other moderators could benefit from, I take it to a moderator-only space. In extreme cases, I’ve removed moderator privileges.
A year ago I was rehired by College Confidential. One of the first things I did was to change the process for suspending users. I communicated this change privately to the moderators and listened to their responses. We worked together to craft a policy that met almost all of our collective goals. One moderator decided they didn’t want to continue moderating with the new policy and resigned. I didn’t like to see them go, but I respect their position. We ended up running our first election to fill out the moderator ranks.
What I’m getting at is that the normal way to correct moderators is privately and collaboratively. I wonder if you can spot when things got abnormal in this timeline:
- November 30 ChatGPT launches.
- December 5 Moderators temporarily ban ChatGPT saying that the final policy needs to be discussed with staff.
- December 8 Staff creates a help center article supporting the temporary ban and explicitly supports the moderators prior work.
- March 28 Stack Overflow’s senior leadership quietly orders the data dump suspended in response to LLMs such as ChatGPT.
- May 30 Stack Overflow’s VP of Community publicly announces a policy that limits moderators from taking action against GPT-generated answers claiming moderators suspended large numbers of legitimate contributors.
- June 7 Stack Overflow’s VP of Community explains the company can’t detect GPT-generated content and thus can’t verify the moderators acted correctly when taking action on suspected GPT content.
I cherry-picked these events, of course. The problem started when leadership focused on ChatGPT without effectively communicating the change internally. It boiled over when the community team forced though a change without laying the proper groundwork. This, by the way, is exactly what happened in 2019. I can practically guarantee senior leadership took no notice of GPT policy on the public sites (and virtually no interest in public sites at all) in December. When leadership did take notice, it refused to listen to the experts on staff who understand how community management ought to work. Much of the arguments presented are post hoc justifications of the decisions leadership forced on them. Or at least that’s my reading of the situation.
True false positive rate of moderator actions
So here’s where we get to my claim that ChatGPT answers are worse than spam. First let’s read what the post asserts about how moderation should work:
Under this assumption, it is impossible for us to generate a list of cases where we know moderators have made a mistake. If we were to do so, it would imply that we have a method by which we can know that the incorrect action was taken. If we could do this, we would share our methods in a heartbeat in the form of guidance to the moderator teams across the network, and then we’d carry on with things as normal. Instead, the most we can do is state that we just can’t tell. We lack the tools to verify wrongdoing on the part of a user who has been removed, messaged, or had their content deleted, and this is a serious problem.
Many people intuitively agree with this conclusion. We expect rules to be clear and either you are following them or not. Most people could compose a solid rule against spam in a few minutes. Over time it probably will need refining, but most everyone can agree on the broad outline. Once you have a rule, it’s easy enough to divide content into “spam” or “not-spam”. As long as you avoid posting “spam” you know you are safe.
But there’s a sort of negative behavior that you can’t write a clear rule to cover. I’ll let Catija explain:
There’s a concept on SE that doesn’t exist in law. That of “breaking the community”. It’s not uncommon for someone to be technically following all the rules while still being disruptive enough that they’re causing a huge amount of harm to others or work for moderators. This is a concept that can be difficult for some to understand but it’s an important one. If they’re barely toeing the line all the time, that’s a huge stress on the community. That said, it’s extremely unlikely someone would get a network-wide suspension for that.
Over the years we’ve seen this with spam’s close cousin, self-promotion. Some people talk about their product and service well past the socially acceptable limit while scrupulously following the community rules. If you write more rules, these folks will find other limits to push. It’s not anybody’s fault, but their goals aren’t the same as the community goals. As Clay Shirky puts it:
Because of the difficulty in maintaining a focus on sophisticated goals, all groups of any integrity have a constitution. There is always an informal piece of the Constitution, and there is sometimes a formal piece as well, an explicit and publicly examinable piece. At the very least, the formal part is what’s instantiated in code—“the software works this way.” The informal part is the sense of “how we do it around here.” And no matter how it is substantiated in code or written in charter, whatever, there will always be an informal part as well. You can’t separate the two.
Everyone can agree spam isn’t welcome. What the company asserts is that we can’t have rules about ChatGPT unless they can be formally written down and since we can’t write such rules to their satisfaction, moderators can’t take action on suspected GPT content. Unfortunately, the core community won’t accept this endpoint because it invalidates the reason they are here.
Stringing it all together
We’ve gone on quite a bit and this section has a few more assertions that don’t hold water, in my opinion. Rather than spend more time as a critic, let’s loop back to 8½, which I did finish in the course of writing this post. In the film, the director decides to cancel the science fiction film he’s been laboring on. His critic congratulates the director’s decision:
You’ve made the right choice. Believe me, today is a good day for you. These are tough decisions, I know. But we intellectuals, and I say we because I consider you such, must remain lucid to the bitter end. This life is so full of confusion already, that there’s no need to add chaos to chaos. Losing money is part of a producer’s job. I congratulate you. You had no choice. And he got what he deserved for having joined such a frivolous venture so lightheartedly. Believe me, no need for remorse. Destroying is better than creating when we’re not creating those few, truly necessary things. But then is there anything so clear and right that it deserves to live in this world? For him the wrong movie is only a financial matter. But for you, at this point, it could have been the end.
Stack Overflow was created in a collaboration between a company and a small community of enthusiasts. Unless you were a programmer before it existed, you simply can’t fathom the luxury of being able to type a few keywords into a search engine and get back an answer from someone who truly understood your struggle. It spawned a network of sites that answered questions in other fields too. Hundreds of thousands of people worked together to create a library of answers to questions that, perhaps, very few people will ever ask.
Machines, even machines with massive resources and data, can never understand the questions they are asked or the answers they produce. For commonly written about questions, modern large language models produce outstanding results. But because they are programmed to be accommodating, they will also provide answers to new questions about which they have little data to work with. Currently there’s no way for humans to know how much they can trust answers produced by machines.
If ChatGPT threatens the company’s business model, it is only because the company (as a whole) has lost track of Stack Overflow’s purpose. This isn’t news, unfortunately. I only hope, before it’s too late, the company will relearn how to work with the volunteers at the core of Stack Overflow rather than against them.
I’m told it was not a birthday present for me.↩︎
These graphs are very noisy, however. Better to look at posts for Math. Physics and Super User.↩︎
Moderators tell me they didn’t actually do this. Instead they kept to the regular suspension process.↩︎
These aren’t my scare quotes. I’m following the post’s lead.↩︎
Evidence that includes my parents, who are college professors, and co-workers starting around the same time I took notice.↩︎
The Stack Overflow graph shows exactly when moderators just stopped deleting posts (and their comments) that are suspected of being ChatGPT-generated.↩︎
I removed a whole section asserting that copying ChatGPT answers with code would require more editing to look right. Then I noticed there’s a button that automatically saves output into nicely formatted Markdown all ready to paste into an answer box. It’s annoying to throw away a bunch of research, but my understanding of the situation was greatly improved by doing the work. It also lets me know that I am following Cromwell’s rule while writing this.↩︎
Unfortunately it still missed my actual problem. An analogy might be if I asked “My timer didn’t go off, so I burned my casserole. How can I prevent this in the future?” A good answer would help me diagnose the problem with the timer. The answer I got was to set a timer so that my casserole won’t burn. I mean, yes, but I already knew about that. Catch up!↩︎